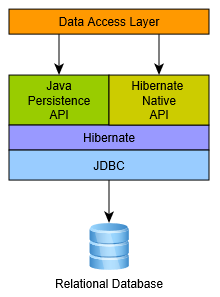
JPA je java persistence api špecifikácia. Na to, aby si mohol používať JPA v skutočnej aplikácii, potrebuješ implementáciu JPA. Buď použiješ servery, ktoré už ponúkajú implementáciu JPA, ako napríklad GlassFish, alebo použiješ implementáciu, ktorú ti poskytuje framework Hibernate alebo EclipseLink.
Ak používame JPA štandardy, tak je v budúcnosti úplne jedno, akú implementáciu JPA budeme používať. Pri programovaní budeme používať JPA anotácie, ktoré pochádzajú z balíka javax.persistence. V budúcnosti môžeš nasadiť aplikáciu na GlassFish, ktorý pozná javax.persistence a vie s tým pracovať alebo na Tomcat s použitím Hibernate, ktorý tiež pozná javax.persistence a vie s tým pracovať.
Čo je Persistence?
Ak vytvoríš hocijaký jednoduchý objekt, čo sa stane? Napríklad objekt Adresa? Vytvorí sa v halde – v pamäti. Objekt môže mať nasetované nejaké dáta – informácie. Ak sa ale stratí referencia v javovskom kóde na tento objekt v halde – tak sa zmaže.
Ak si chceme uchovať tieto informácie, tak ich môžeme uložiť do databázy a najlepšie, aby po vytiahnutí z databázy mali tieto dáta tú istú formu – teda formu objektu Adresa.
Tomuto sa hovorí, že persistujeme (uchováme stálosť) objekt do databázy. Akoby tento objekt existoval aj mimo java programu. Tento objekt sa uchová v úložisku a znovu sa vytvorí, ak bude treba.
Čo je ORM?
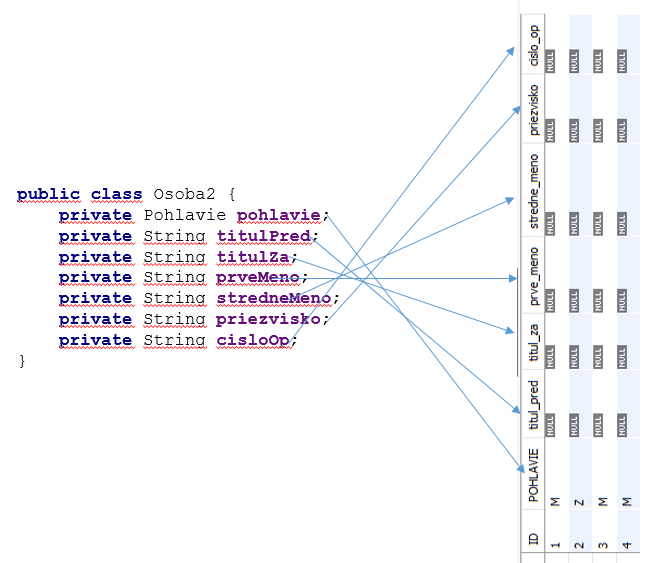
Klasické databázy ako Oracle, MySql a podobne sú relačné databázy, ktoré majú dáta uložené vo forme tabuliek. V jave ukladáme dáta vo forme objektov, v databáze vo forme tabuliek. Ale čo majú podobné? V relačnej databáze máme stĺpce, ktoré majú názvy a v riadkoch máme hodnoty. Niečo ako klúč hodnota – to isté platí aj pre objekty v jave – tam máme názov premennej a hodnotu v nej uloženú.
Tu prichádza pod ruku ORM – teda object relational mapping. Je to niečo ako objektovo relačné mapovanie. My naše java objekty namapujeme na tabuľky relačnej databázy. Aby sme vedeli, že tento field v javovskom objekte patrí do tohto stĺpca.
Objekty v jave sú medzi sebou prepojené pomocou uloženia referencie na daný objekt. Napríklad človek má field Adresa, kde je uložená referencia na objekt Adresa.
Relačné tabuľky majú medzi sebou tiež väzby. Buď máme v tabuľke pre človeka stĺpec adresa, kde bude uložený identifikátor adresy a na základe tohto identifikátora nájdeme danú adresu. Alebo existuje špeciálna tabuľka, kde budú dva stĺpce jeden pre identifikátor adresy a druhý pre identifikátor človeka. My potom vieme nájsť, aké adresy má človek nastavené, alebo pre akého človeka je nastavená daná adresa.
Problém s JDBC prístupom – výhoda ORM
V kurze Java pre pokročilých, ak si tento kurz videl, sme si ukazovali prístup k databáze cez JDBC. Čo sme spravili? Otvorili sme konekciu na databázu, napísali sme sql príkaz, ktorý sme následne poslali do databázy na vykonanie. Databáza nám vrátila výsledok vo forme result setu.
Predstav si, že máš len 5 až 10 tabuliek. Nad každou tabuľkou máš napríklad 4 rôzne sql príkazy – to máme približne 20 – 40 sql príkazov. Ak sa ti stane, že musíš zmeniť databázu – napríklad zmeníš názov stĺpca v tabuľke? Čo musíš spraviť? Musíš prepísať názov tohto stĺpcu na xy miestach – na 20 až 40 miestach – a to sme len v malej aplikácii – čo ak by to bolo na 100 miestach?.
Bol by v tom neporiadok a mohli by nastať problémy.
Ak ale použijeme ORM, tak v jave pracujeme s naším kódom, tak ako bežne. Vytvoríme si objekty typu Clovek, nastavíme mu nejaké hodnoty. Ďalej si vytvoríme kolekciu Adries pre daného človeka. Nakoniec v ORM frameworku povieme len persistni mi tento objekt. ORM sa potom postará o všetko uloženie týchto objektov do databázy na základe mapovania, ktoré mu poskytneme.
Clovek clovek = new Clovek();
clovek.setMeno("Jaro");
clovek.setPriezvisko("Beno");
Adresa adresa1 = new Adresa();
adresa1.setUlica("Nejaka 5");
adresa1.setPSC("94404");
Adresa adresa2 = new Adresa();
adresa2 = new Adresa();
adresa2.setUlica("Nejaka 5");
adresa2.setPSC("94404");
List<Adresa> adresaList = Arrays.asList(adresa1, adresa2);
clovek.setAdresaList(adresaList);
orm.persist(clovek);
Ak by sme nepoužili ORM, sami by sme museli napísať metódu, ktorá nám otvorí konekciu na databázu, museli by sme napísať INSERT SQL príkaz pre človeka a potom aj pre jeho adresy a museli by sme zabezpečiť, aby sme nastavili všade dáta tam kde majú byť a musíme sa postarať aj o prepojenia medzi týmito dvoma objektami.
Ak ale použijeme ORM, tak sa nemusíme starať o tento balast kódu, ale sústrediť sa najmä na to, čo predáva a to je business logika aplikácie.
Nevýhody JDBC prístupu sú teda, že máme príliš veľa SQL príkazov, veľmi veľa kópie kódu, ručne sa musíme postarať o nastavenie dát do správnych stĺpcov.
Výhodou ORM je, že nemusíme robiť tieto veci z predchádzajúcej vety. ORM nám umožní používať java objekty na reprezentáciu relačnej databázy. ORM sa nám postará aj o prepojenie závislostí. ORM spojí výhody relačnej databázy a objektového modelu v jave plus schová všetku komplexitu SQL príkazov.
Čo je Hibernate?
Hibernate je ORM – object relational mapping framework, ktorý slúži na mapovanie java objektov na tabuľky relačných databáz.
Java programátori sú zvyknutí písať kód v objektoch, prečo teda potrebujú ďalší jazyk – sql – na získanie dát z databázy? Hibernate na pozadí sám vytvára sql príkazy nad databázou a preto nemusíme písať sql príkazy my.
Ak chceme uložiť mapu objektov, napríklad Cloveka, ktorý ma Adresu, alebo aj viac objektov typu Adries, tak nemusíme písať všetky sql príkazy. Stačí, ak zavoláme jednoduchú metódu na uloženie objektu do databázy a hibernate sa postará o zvyšok.
Hibernate je aj implementácia JPA.
Čo je JPA?
Skratka JPA je Java Persistence API. Čo to znamená? V jednoduchosti povedané – je to štandard. Trošku zložitejšie povedané – je to špecifikácia pre OR mapovanie a je súčasťou Java EE, ale môžeme ju používať aj v Java SE projektoch.
Niektoré servery poskytujú vlastnú implementáciu JPA a niektoré nie – v tom prípade použijeme napríklad Hibernate implementáciu.
Predstav si, že celý tvoj kód používa veci z JPA. Teraz je na tebe, kam nasadíš svoju aplikáciu. Ak ju nasadíš na Glassfish nemusíš prerábať svoj kód, ktorý používa JPA – Glassfish ho pozná. Ak svoju aplikáciu nasadíš na Tomcat, tak mu prihodíš Hibernate, ktorý tiež pozná JPA. Potom tvoj kód bude fungovať všade – lebo používa štandardy JPA.
Je možné aby sme používali len Hibernate – teda by sme nepoužívali nič zo štandardov. Žiadne anotácie z javax.persistence a podobne – to ale neodporúčam.
Pýtal som sa
Napadlo mi, že by nebolo od veci spýtať sa kolegov developerov, čo si myslia o JPA a Hibernate. Ak by si si chcel prečítať ich názory, nech sa páči – bez cenzúry, citujem:
Tak toto je náročná téma a navyše zložitá.
JPA resp. ORM všeobecne (a teda aj Hibernate) sú vždy zložitejšie, než si používatelia (t.j. vývojári) uvedomujú. Výsledkom sú často nenápadné chybičky, lazy load exceptions, ktoré vedú k anti-patternom ako je OSIV (open session in view) alebo k výkonovým problémom (n+1 problem).
Týchto problémov je typicky o to viacej, o čo zložitejšie je mapovanie – a pritom práve na riešenie zložitého mapovania bolo ORM vymyslené. Aby sme mohli namapovať doménu do DB. Na to, sa často používajú aj “mimojazykové” triky ako reflection na private polia, takže objekty sú implicitne zviazané s ORM riešením, aj keď napr. mapovanie je oddelené do XML namiesto anotácii, čo samo o sebe je tiež nepraktické.
Okrem toho majú obe hlavne implementácie dosť bugov na to, aby na ne človek narazil, aj keď postupuje v súlade so špecifikáciou – stačí len chcieť trosku viacej a na nejaký bug určite narazíte. Takže potom to je kľučkovanie medzi bugmi a často komplikovaná možnosť vymeniť ORM providera.
Čo sa mi na ORM páči je lepšie mapovanie typov, možnosť customizovať mapovanie a podobne. Preto používam JPA aj na jednoduché mapovačky namiesto JDBC.
Navyše s JPA používam rad Querydsl, ktoré je lepšie/intuitívnejšie, než JPA štandardné Criteria API.
Hibernate používam dlho ale pravdu povediac nikdy som sa veľmi nezamýšľal nad výhodami. Zatiaľ som nemal výraznejší problém, ktorý by som nevedel vyriešiť, prípadne nejako obísť.
Plusy:
- ľahko sa robí mapovanie do DB s anotáciami aj pre začiatočníka bez veľkých znalostí databázy, zároveň ale bez znalosti DB môže byť mapovanie neefektívne
- je open source, takže ak potrebujem, viem pozrieť zdrojáky ako funguje
Mínus:
- asociácia OneToOne fetch=lazy nefunguje
Na používaní Hibernate/JPA (celkovo ORM vrstve) sa mi páči:
A) Abstrakcia od fyzického dátového modelu. Vývoj nad doménovým/logickým (entitno-relačným dátovým modelom) - bližšie k biznis vrstve. Čiže zjednodušené práca s objektami namiesto tabuliek.
B) Možnosť využívať rôzne pokročilejšie techniky získavania dát (napr. Spring Data JPA, ale aj zjednodušujúce Hibernate Query by example)
C) Agnostické od konkrétnej databázovej technológie (Oracle, MySql, ...)
D) Cachovanie a optimalizácia (napr. lazy loading)
Nevýhody:
A) Niekedy náročný (až nemožný) performance tuning.
B) Pri niektorých technológiách pomalšia krivka učenia.
C) Aj napriek používaniu JPA/Hibernate, je takmer nevyhnutné, aby developer poznal aj (native) SQL jazyk a jeho použitie.
Záver
Podarilo sa ti nazrieť do problematiky objektovo relačného prístupu k databáze a pochopil si, čo to znamená. Ak sa však chceš dostať ešte o level ďalej, pripravili sme pre teba samostatný kurz Java persistence – JPA a Hibernate.
🥇 Sme jednotka v online vzdelávaní na Slovensku. Na našom webe nájdeš viac ako 300 rôznych videokurzov z oblastí ako programovanie, tvorba hier, testovanie softwaru, grafika, UX dizajn, online marketing, MS Office a pod. Vyber si kurz, ktorý ťa posunie vpred ⏩